Master's Thesis
Overview
Learning from Play is a Machine Learning based method which uses play data to train a model to complete any goal in the environment. Play data is data collected with a layman operator exploring and manipulating the environment without any specific goal. This has advantages over Imitation Learning because it does not require an expert operator or a task specific dataset. It also does not require an accurate simulator or extensive on robot training time like Reinforcement Learning does. Previous literature 1234 did learning from play on a single arm robot. For my thesis I expanded this work to a bi-manual robot. The full thesis is here.
Environment Setup and Data Collection
The environment consisted of two Koch 2.0 leader robots and two Koch 2.0 follower robots and a single overhead webcam. Play data is collected by teleoperating the robots. For my project I collected 3 hours of joint angle and image data.

Framework
The Play-LMP framework was introduced by Lynch et al., 20201. During the training phase, a random sequence is taken from the play data. The images are fed through the CNN-based Vision Network to generate the vision features. Then the full sequence is encoded into a latent plan distribution with the GRU-based Plan Recognition Network. This latent plan is then sampled and decoded with the GRU-based Policy Network into an action sequence using the goal image and current state. The likelihood between the input sequence and the decoded sequence is minimized to improve action reconstruction. Additionally during training, the start state, start image and goal image are encoded into a latent plan using the MLP-based Plan Proposal Network. The Plan Proposal Network is the only encoder used during testing so the KL-divergence between the latent plans produced by the Plan Recognition Network and Plan Proposal Network is also minimized during training. During testing, the start state and a user selected goal image are encoded into the latent plan with the Plan Proposal Network and then decoded in the same way as training. Exact model architectures are specified in the thesis.
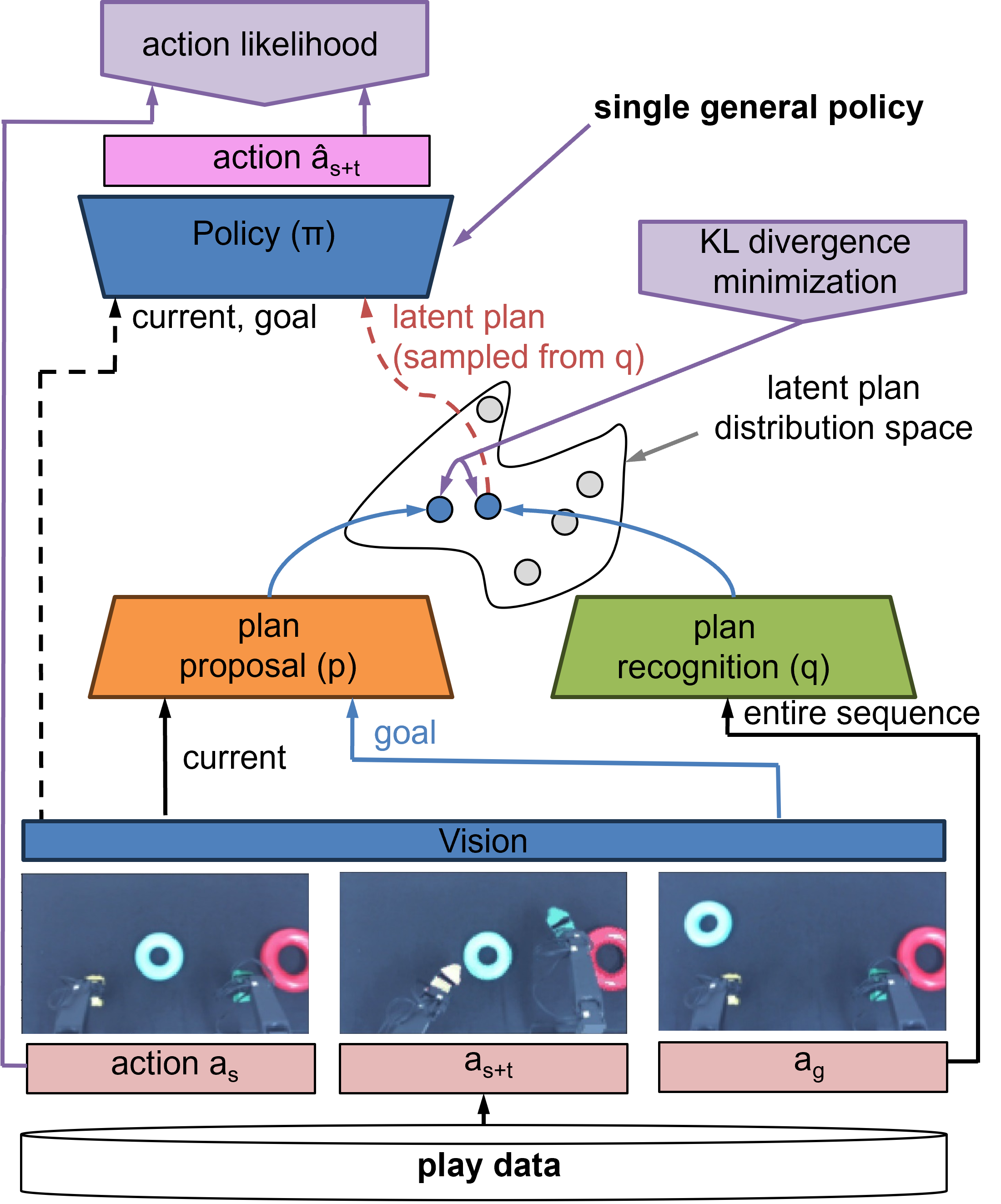
Training Framework, adapted from 1.
Testing Framework, adapted from [^1].
Results
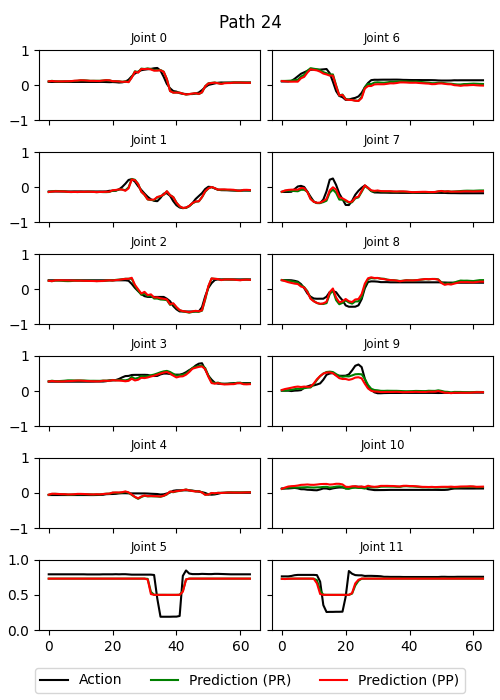
Path Reconstructions
Path reconstructions using both the Plan Recognition Network and Plan Proposal Network latent plans during offline testing follow the original closely. More reconstructions shown in thesis.
Vision Features
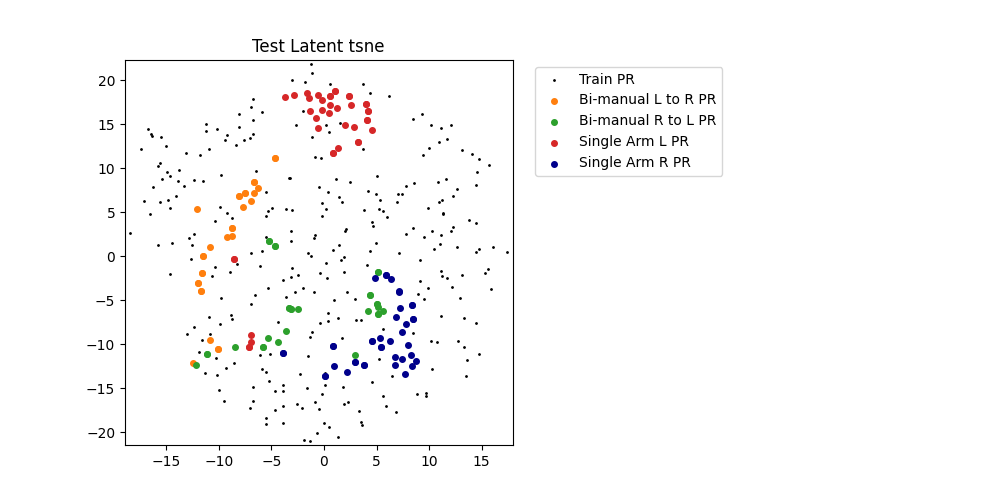
Latent Features
For the latent features we want to see separation between different movement types within the latent space. This shows that the latent space is producing a meaningful encoding rather than being shrunk to zero in order to minimize KL-divergence between the Plan Recognition Netowrk and Plan Proposal Network latent spaces.
-
Corey Lynch et al. “Learning Latent Plans from Play”. In: Proceedings of the Conference on Robot Learning. Ed. by Leslie Pack Kaelbling, Danica Kragic, and Komei Sugiura. Vol. 100. Proceedings of Machine Learning Research. PMLR, 30 Oct–01 Nov 2020, pp. 1113–1132. URL: https://proceedings.mlr.press/v100/lynch20a.html. ↩ ↩2 ↩3
-
Zichen Jeff Cui et al. From Play to Policy: Conditional Behavior Generation from Uncurated Robot Data. 2022. arXiv: 2210.10047 [cs.RO]. URL: https://arxiv.org/abs/2210.10047. ↩
-
Keigo Ishii et al. “Goal-Conditioned Flexible Object Manipulation by Self-Supervised Learning from Play”. In: 2023 IEEE International Conference on Development and Learning (ICDL). 2023, pp. 150–155. DOI: 10.1109/ICDL55364.2023.10364471. ↩
-
Chen Wang et al. MimicPlay: Long-Horizon Imitation Learning by Watching Human Play. 2023. arXiv: 2302.12422 [cs.RO]. URL: https://arxiv.org/abs/2302.12422. ↩